

S3 Replication is a fully-managed Amazon Web Services (AWS) feature for replicating objects and their metadata across one or more S3 buckets. And with cross-region replication (CRR), you can use this feature to replicate objects across buckets located in different AWS regions. CRR is useful for:
- Meeting compliance requirements that demand certain data be stored in geographically dispersed regions.
- Minimizing latency for users by moving data physically closer to them.
- Disaster recovery by minimizing data loss via backups and active/passive or active/active failover strategies.
You can implement CRR with the native Amazon S3 Replication or use Resilio Connect to achieve fast, reliable, and efficient replication across any AWS region and service (or even other cloud providers and on-prem environments).
In this guide, we’ll start by showing you how to set up CRR using S3 Replication and cover the five key steps for setting up replication between buckets in different regions — from creating Amazon S3 buckets to configuring a replication rule and more.
In the second part of this guide, we’ll show you the benefits of CRR with Resilio Connect. Specifically, you’ll learn how Resilio Platform makes replication:
- Faster due to its scale-out P2P architecture and WAN optimization technology.
- Simpler due to the ability to manage the entire replication process (even in a multi or hybrid cloud scenario) from a single place.
- More reliable through resilience, eliminating single points of failure (SPOF) including the ability to route data dynamically around failures.
- More efficient due to the ability to minimize data transfer costs by storing frequently accessed data locally, pinning traffic to an optimal network, and more.
- More flexible through hybrid deployment and replication options, e.g., you can replicate data within or across AWS regions and services, or use other cloud providers and on-prem environments.
Companies like Exxon Mobil, KFC, and Blizzard use Resilio Platform for fast, efficient, and flexible replication. To learn how Resilio Platform can help you achieve fast and reliable CRR, schedule a demo with our team today.
How to Set Up S3 Cross-Region Replication (in 5 Steps)
In this section, we’ll talk through five basic steps for configuring CRR:
- Creating S3 buckets in different regions
- Configuring a replication rule
- Setting up IAM roles
- Adjusting other options
- Monitoring the replication process
We’ll also provide links to relevant AWS tutorials if you need more context around a particular step or topic. If you already know how to do this and just want to learn how to make cross-region replication faster, you can skip ahead here.
1. Create S3 Buckets in Different Regions
Creating a new S3 bucket is pretty straightforward. Just log into the AWS Management Console, open S3, choose “Buckets” from the menu on the left, and click on “Create bucket”.
From here, you can:
- Select the bucket’s region.
- Give it a descriptive bucket name. For example, you can put the region and either “source” or “destination” in the name, so you don’t get it confused later on.
- Enable versioning. In order for replication to work, both the source and destination buckets must have versioning enabled.
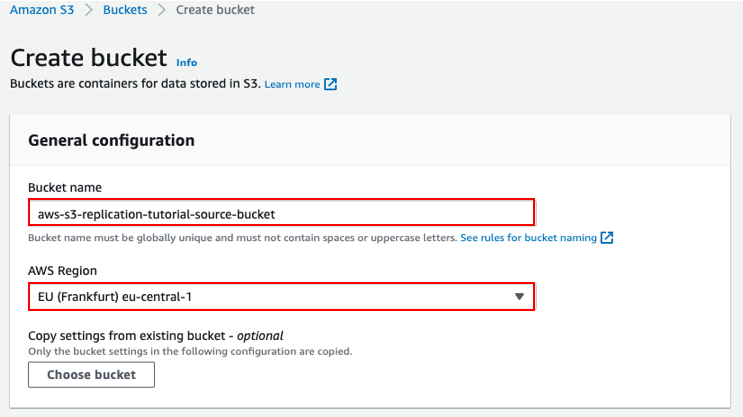

After that, just repeat the process to create another bucket in a different region.
2. Configure a Replication Rule
Select the bucket you want to use as a source and go to “Management” → “Replication rules” → “Create replication rule”.
You can give the rule a descriptive name and choose “Enabled” if you want it to start working after being created.
You can also give it a priority number — the lower that number, the higher the priority of the rule. For example, the S3 objects under a priority 1 rule will get replicated before ones under a priority 2 rule, and so on.
Once the rule is enabled, you can select:
- The destination bucket. Note that if the destination bucket is owned by a different AWS account, you’ll need to go through a few extra steps. Check out our article on S3 cross-account replication for more details.
- Which objects to replicate. You can replicate the entire bucket or define a filter type to only replicate certain objects, e.g., existing objects that are in a certain prefix. You can get step-by-step instructions on how to do this in AWS’ replication configuration tutorial.
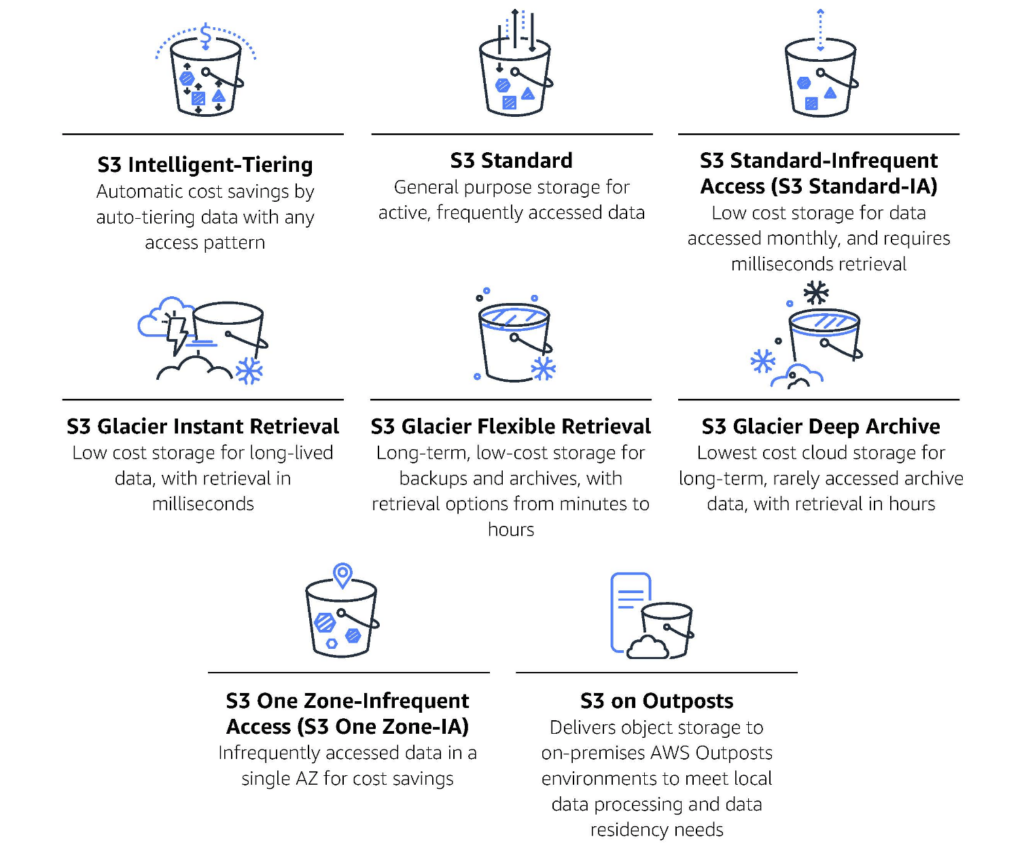
- The storage class for the replicated objects in the destination bucket. Amazon Simple Storage Service offers 8 different storage classes. Each of these is suitable for different workloads and budgets, so there’s no universally right or wrong choice here.
3. IAM Considerations
AWS Identity and Access Management (IAM) lets you specify who has access to specific services and resources.
In order for replication to work, the IAM role associated with your replication configuration must have sufficient permissions to write new objects in the new destination bucket.
If you’ve used S3 Replication before, you likely already have an IAM role, which you can select from the “Choose from existing IAM roles” option. If not, you’ll need to create a new IAM role that gives Amazon S3 permissions to read and replicate objects.
Here’s one example of such an IAM policy from AWS’ documentation:
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"s3:GetReplicationConfiguration",
"s3:ListBucket"
],
"Resource":[
"arn:aws:s3:::DOC-EXAMPLE-BUCKET1"
]
},
{
"Effect":"Allow",
"Action":[
"s3:GetObjectVersionForReplication",
"s3:GetObjectVersionAcl",
"s3:GetObjectVersionTagging"
],
"Resource":[
"arn:aws:s3:::DOC-EXAMPLE-BUCKET1/*"
]
},
{
"Effect":"Allow",
"Action":[
"s3:ReplicateObject",
"s3:ReplicateDelete",
"s3:ReplicateTags"
],
"Resource":"arn:aws:s3:::DOC-EXAMPLE-BUCKET2/*"
}
]
}
In this example, DOC-EXAMPLE-BUCKET1 is the source bucket and DOC-EXAMPLE-BUCKET2 is the destination. The policy grants access to Amazon S3 to retrieve the replication configuration and list the bucket content. It also lets S3 get a specific object version and the access control lists (ACLs) associated with it, as well as replicate and delete markers to the destination bucket.
4. Additional Options
Besides the fundamental settings from the previous three steps, S3 Replication also offers many optional features. The most popular of these are:
- Encryption: SSE-S3 is the default S3 encryption but you can also use AWS Key Management Service (KMS) for server-side encryption. If you use KMS encryption, you will need to provide the KMS keys to decrypt in the source bucket and re-encrypt in the destination.
- S3 Replication Time Control (S3 RTC): This feature guarantees that 99.99% of objects will be replicated within 15 minutes. It’s useful for meeting business and compliance requirements, so you can enable it if you rely on your data being replicated as quickly as possible.
- Replication metrics and notifications: This option gives you detailed metrics to track the replication progress, including bytes and operations pending, replication latency, and more. Note that you’re going to be monitoring the progress through Amazon CloudWatch, which comes with separate metrics fees.
5. Review and Monitor the Replication Process
After adjusting all the settings, you can go back and review the entire replication configuration. To test if everything’s working correctly, you can upload a new object to the source bucket and wait to see if it gets replicated to the destination.
If there are no issues, you can upload the rest of your objects and start monitoring the replication process. This can be done by opening the source bucket, clicking on the “Metrics” tab, and checking out the operations pending replication, bytes pending replication, and replication latency for your replication rule.
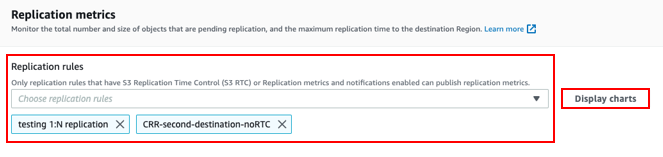
If you enable replication metrics and notifications as we showed in the previous step, you can also use Amazon CloudWatch to get more detailed info about each replication rule, as well as the source and destination buckets.
How to Speed Up and Simplify Cross-Region Replication with Resilio Connect
As you can see, S3 Replication is complex and time-consuming to set up. Additionally, it can also be:
- Slow and unpredictable, especially when replicating lots of objects across geographically distributed regions. Unlike same-region replication (SRR), there’s no easy way to guarantee all your objects will be replicated quickly in every CRR scenario. As we explained in our guide to AWS cross-region latency, this makes the process of estimating and reducing replication latency very difficult.
- Expensive, especially when moving lots of data across regions. Cross-region data transfer rates are often very difficult to calculate in advance, as many different factors affect object replication pricing. And because of AWS’ complexity, many companies move more data than necessary, often resulting in much higher replication costs than expected.
Fortunately, Resilio Platform can help you avoid both issues.
Resilio Platform is our replication solution that delivers industry-leading replication speed thanks to its organically scalable P2P design and proprietary WAN transfer technology. For example:
- Larian Studios uses Resilio Connect to move data between their locations five times faster.
- VoiceBase uses Resilio Connect to speed up their code distribution time across 400 servers by 88%.
- Wargaming uses Resilio Connect to quickly synchronize 50GB game builds between 20 offices.
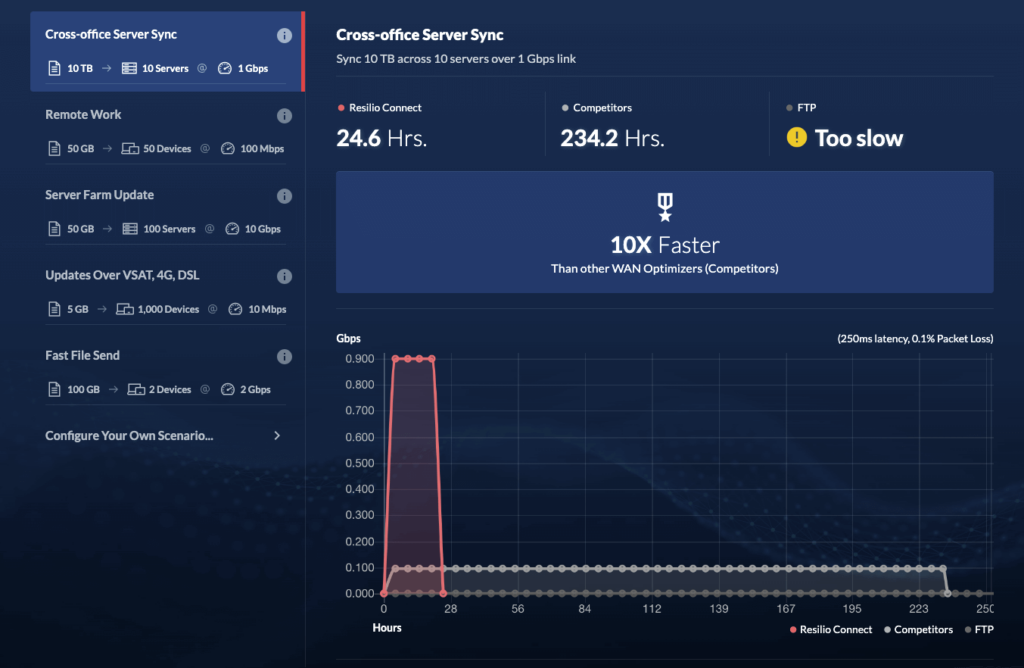
Besides typically being between 3 and 10 times faster than traditional replication solutions, our software is also:
- Flexible, as you can use it with any cloud provider (Amazon Web Services, Google Cloud, Microsoft Azure, etc.) and deploy it on-prem or in a hybrid cloud environment.
- Much simpler to set up and use, because you can deploy it on your existing infrastructure (no need to get new hardware or migrate data) and start replicating in as little as two hours.
- Secure by default, as it encrypts data at rest and in transit using AES 256.
- Cost-efficient.
- And much more.
In the next sections, we’ll discuss five key benefits of using Resilio Platform to replicate your data across regions.
Fast, Reliable, and Fault-Tolerant Replication
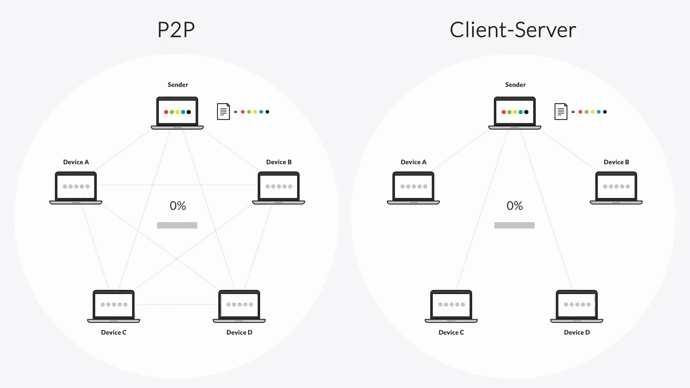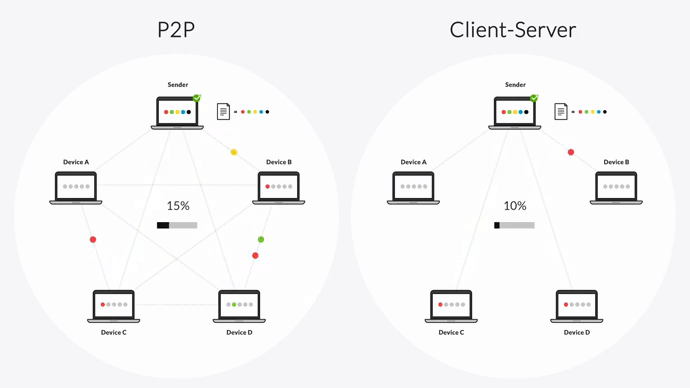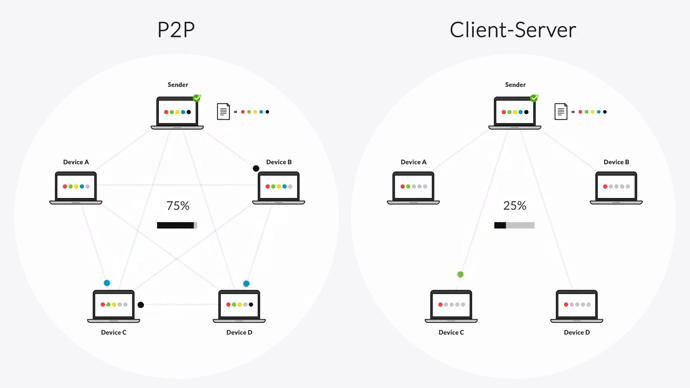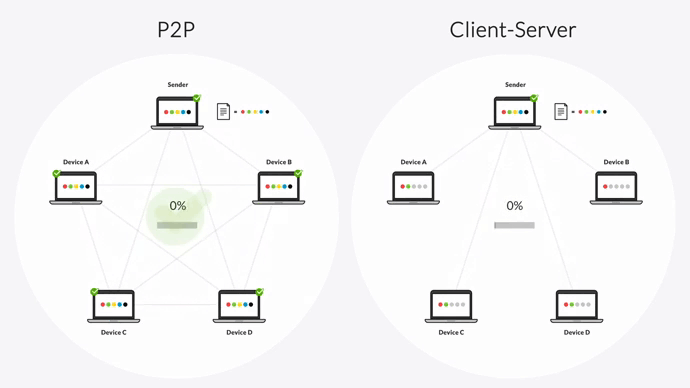
Most traditional replication and file transfer solutions are TCP-based and use a point-to-point architecture. But Resilio Platform relies on a unique peer-to-peer (P2P) topology and WAN optimization technology which lets it achieve much faster replication times while being more reliable and fault-tolerant.
Here’s why:
The two most widely-used replication topologies — client-server and “follow-the-sun” — have downsides that prevent them from producing fast replication speeds.
- In a client-server scenario, only one device (the hub) can replicate data across the entire environment. For example, if Client 1 wants to replicate data across the other clients, it has to first share that data with the hub.
- In the “follow-the-sun” scenario, replication can only occur sequentially, from one device to the next, e.g., Device 1 must replicate objects to Device 2, which then replicates them to Device 3, and so on.
In both cases, replicating is always limited to one device at a time. This inevitably leads to slower replication since the process can only take place between two devices at a time. It also creates a single point of failure, since any sort of issue with the replicating or receiving device — like a slow network or outage — can obstruct the replication to all other devices.
Also, most solutions use TCP for transfer over WANs (wide area networks). This further slows down replication speeds since TCP struggles with WAN transfers. Packet loss and latency, which are defining characteristics of WANs, both disrupt TCP, leading to replication delays and an inability to make the most out of expensive WAN connections.
Resilio Connect’s unique P2P architecture and WAN optimization technology help you avoid both issues.
First, our software’s P2P architecture lets every device replicate data to the others in your environment. This means replication isn’t limited to a single device, so there’s no risk of your replication environment failing.
Our solution can also turn files into several chunks when replicating data. This process — called file chunking — lets every separate part be transferred independently, leading to transfer speeds that are between 3 and 10 times faster than traditional replication solutions.
The unique P2P architecture and the ability to hash files in chunks makes Connect one of the few replication platforms that can reliably perform bidirectional and multi-directional sync. With Connect you can transfer or sync files in any direction:
- One-to-one.
- One-to-many.
- Many-to-one.
- N-way (or many-to-many).
N-way transfer makes Resilio Platform an ideal solution for syncing large numbers of servers (because every server can sync across the entire environment) and collaborating efficiently in a remote or distributed workforce (because everyone, regardless of their location, can make and share file changes with others instantly).
Second, Resilio Connect’s proprietary WAN optimization technology maximizes replication speed across any network and overcomes latency and packet loss.
Resilio uses a proprietary UDP-based transfer protocol called Zero Gravity Transport™ (ZGT) that:
- Is optimized for unreliable networks, you can always replicate, send, and ingest data from the edge of a network to a centralized location.
- Maintains a uniform rate of packet distribution over time. The rate is calculated with a congestion control algorithm that periodically probes Round Trip Time (RTT). As a result, our software is always informed about the speed of file transfer over any network.
- Reduces unnecessary retransmissions and sends out interval acknowledgements. Resilio Platform sends acknowledgements for a group of packets (instead of after receiving each packet) and retransmits lost packets once per RTT. These techniques reduce unnecessary retransmissions and make the transfer and replication processes much more efficient.
You can check out our speed calculator to estimate how much time Resilio’s technology can save your organization, depending on your use case.
Finally, Resilio Platform is also an ideal disaster recovery solution because:
- There’s no single point of failure in the P2P architecture. If one device in your environment fails, our software can always access data from the others.
- The ZGT transfer protocol is sensitive to bandwidth changes and can always optimize data transfers. This means that data is dynamically routed around failures to overcome latency and network congestion.
As a result, companies that use Resilio can meet sub-five-second RPOs (Recovery Point Objectives) and RTOs (Recovery Time Objectives) within minutes of an outage.
Simple and Centralized Management
Complexity has always been a big issue with AWS. There are so many services and features you can use for storing, moving, and replicating data that it can be very difficult to find the right one for your use case.
For example, you can replicate data with AWS S3 Replication, AWS DataSync, Amazon S3 Batch Operations Copy, and the S3 Copy Object API. Each has its own strengths and limitations, as shown in the screenshot below.
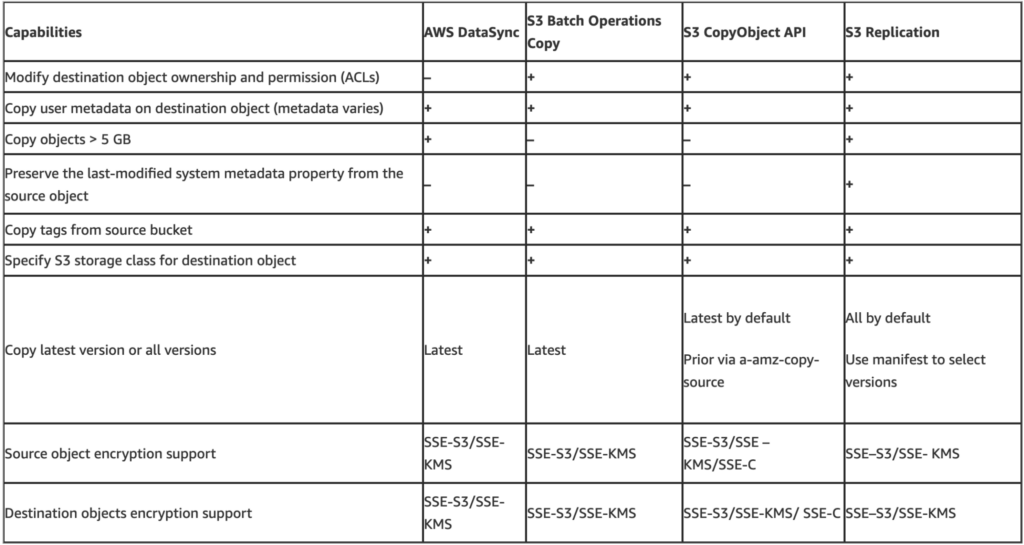
And, as we already said, there are other features for speeding up and monitoring replication, like S3 RTC, KMS, regular replication metrics, replication metrics in CloudWatch, and more.
Resilio Platform helps you avoid that complexity by letting you control the entire replication process from a single place. Regardless of the replication scenario, you can set up, monitor, and control every single replication aspect from the Central Management Console shown below.
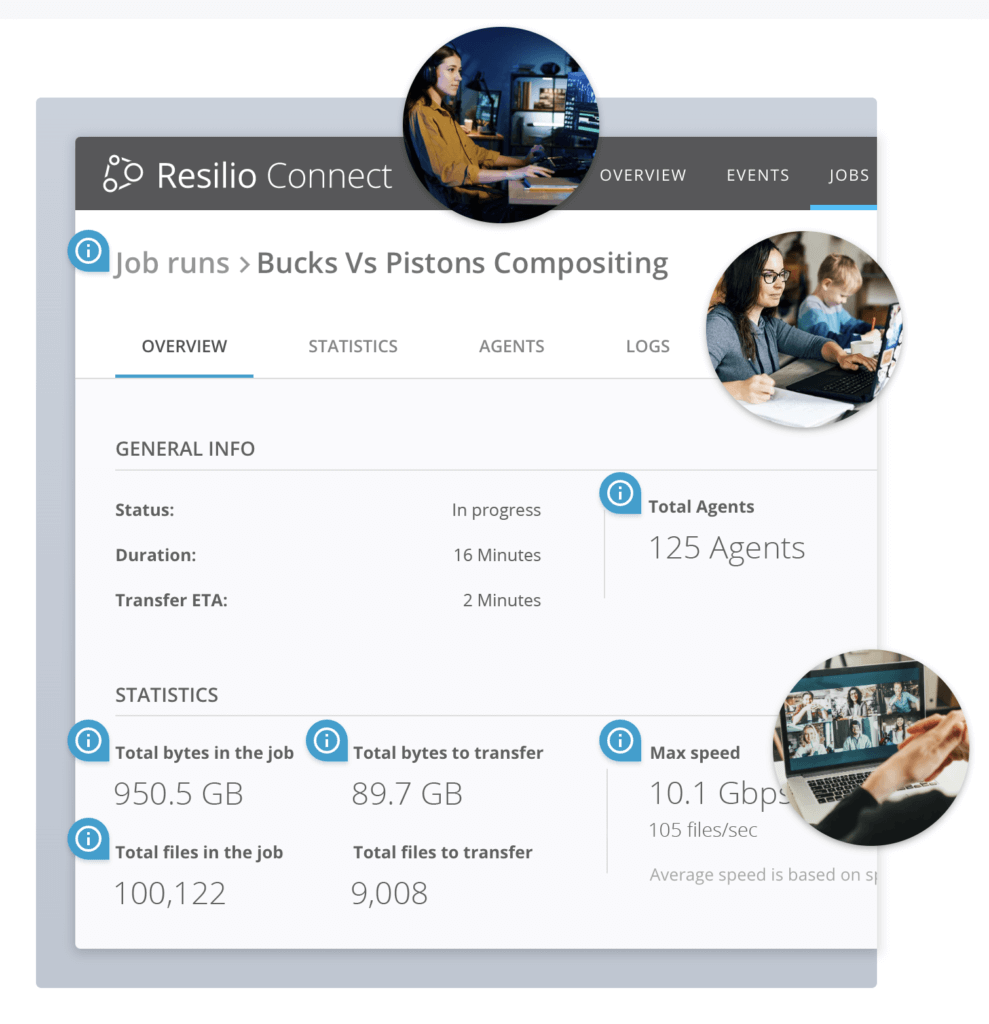
For example, you can use the console to:
- Create, pause, and stop replication jobs.
- Set up and track replication rules, metrics, and notifications.
- Configure replication parameters like buffer size, bandwidth usage policies, and disk I/O threads.
- Configure real time notifications of replication progress that can be delivered via email or Webhooks.
This console can be stored in EC2 and in any Windows or Linux instance (virtual or physical), in another cloud provider, and on-premises.
In terms of simplicity, Resilio Platform also gives users easy, low-latency access to their files from a unified interface (UI). This UI operates much like Microsoft OneDrive, which makes it very easy and intuitive to browse and access the files you need.
For example, MixHits Radio experienced massive time savings (around 60 hours per month) thanks to the simplicity and centralized management of the Central Management Console.
“We have gone from spending 15 hours on average per week troubleshooting conflicts in the prior solution to spending no time at all with Resilio. We configure jobs once in the Resilio Connect Management Console and never have to look at it again.”
— Gary Hanna, CEO of Mixhits Radio
Read the full MixHits Radio case study here.
End-to-End Security by Default
Unlike many file gateway and replication solutions, Resilio Platform comes with built-in security features, including:
- AES 256 encryption for data at rest and in transit.
- One-time session encryption keys for protecting each session.
- Permission controls for granular control (like a bucket policy) over who gets access to specific files and folders.
- Cryptographic data integrity validation which ensures data always arrives at its destination intact and uncorrupted.
- Mutual authentication, which requires any endpoint to provide an authentication key before communicating with another endpoint.
All Resilio security features have been verified by 3rd-party security experts to ensure they’re up-to-date with the strictest security standards.
Deployment and Replication Flexibility
Most replication solutions are single-vendor proprietary. They’re limited to using the product within a platform or cloud. For example, it’s relatively simple to replicate data across AWS using native AWS replication solutions — but these solutions do not interoperate with other cloud providers.
Resilio is multi-cloud and can be deployed on any infrastructure — single-cloud, multi-cloud, hybrid cloud, on-prem, and so on. This means you can:
- Deploy it on your existing IT infrastructure (servers, networks, and desktops) and storage, including NAS, DAS, SAN, and object storage.
- Run it on popular operating systems such as Android, macOS, Linux (a variety of distros), FreeBSD, and Windows. Resilio also runs on a variety of NAS systems, and virtualization platforms like VMware Citrix, and Microsoft FSLogix.
- Blend storage from any type of platform or object storage. You could use S3 on one endpoint and Azure Blobs on another. You could use direct-attached JBODs with hard drives or SSDs. Resilio supports a variety of storage interfaces: file, block, or object.
As a result, you can avoid vendor lock-in and replicate your data across a variety of regions, services, cloud providers, and on-prem storage. For example, Resilio Platform lets you:
- Replicate your data quickly across any AWS region and other services.
- Browse and sync files on file, block, or object storage via popular tools on operating systems like Mac and Windows.
- Replicate your data across a variety of file storage solutions and cloud storage services like AWS, Azure, GCP, Wasabi, Backblaze, and more.

Efficiency
Resilio Connect’s efficient P2P design optimizes replication and data transfer by only sending the changed portion of files in real-time. Efficiency is also obtained by avoiding unnecessary data movement, such as egress via:
- Local file storage cache: it’s easy to keep frequently accessed files on local storage. This results in reduced egress traffic which translates to lower AWS egress costs.
- Transparent Selective Sync (TSS), which enables downloading and synchronizing files on demand. You can browse objects stored in S3 as files, select individual files, and perform an action: download, partially download, or sync; there’s no unnecessary data being transferred off-network or across regions.
- Smart Routing, which lets you choose the optimal network for your traffic, e.g., you can keep the traffic on the AWS network or move parts of it to a remote edge network, so you can use a LAN, instead of a more expensive WAN.
Our engineering team is also constantly looking to boost Resilio’s efficiency. In a recent update, we optimized time, merging, CPU usage, indexing, storage I/O, and end-to-end transport — reducing the average memory footprint required on replication jobs by 80%.
Achieve Fast, Reliable, and Efficient Cross-Region Replication with Resilio Connect
Resilio Platform can help you replicate data extremely fast across any AWS region, other cloud providers, and even on-prem environments.
Our software’s P2P architecture and WAN optimization technology make it an incredibly fast, reliable, and scalable replication and storage solution. Resilio Platform is also:
- Secure, thanks to the built-in AES 256 encryption.
- Highly resilient, as it doesn’t have a single point of failure.
- Easy to manage because you can set up, monitor, and control the entire replication process (even in multi or hybrid cloud scenarios) from one Central Management Console.
- Flexible because it can be deployed on any cloud, on-prem, or hybrid cloud infrastructure. You can also use it to store and replicate data across any storage type — NAS, DAS, SAN, object storage, file storage, block storage, and more.
Ready for a live demo? Click here to schedule a demo with our team.



